AIの深層学習用ニューラルネットワークモデル向け自動圧縮・実装ツールを開発
―モデルサイズを最大約1/30に圧縮、エッジデバイスでの高度AI処理を実現―
2019年11月18日
NEDO(国立研究開発法人新エネルギー・産業技術総合開発機構)
株式会社アラヤ
NEDOは、ハードウェアからアプリケーションまでを見越したネットワークの末端(エッジ)側での超低消費電力エッジコンピューティング技術の開発を行っており、今回、(株)アラヤとともに、人工知能(AI)の深層学習用ニューラルネットワークモデルを自動で最大約1/30に圧縮し、FPGA(Field Programmable Gate Array)に実装するツールを開発しました。
本ツールでモデルサイズを圧縮し、生成されたソースコードを、AI処理を行うFPGAに実装することにより、自動車やスマートフォンなどのネットワーク末端機器(エッジデバイス)上で、省電力・省スペースでリアルタイムでのAI処理が可能となります。また、圧縮や実装の工程が自動化されることにより、高度なAIの開発期間の短縮や開発コストの低減を実現します。
なお、本ツールは、(株)アラヤが「Pressai(プレッサイ)」の名称で、2020年3月より提供開始する予定です。
1.概要
IoT社会の到来により、データ量が爆発的に増加する中、それらのデータの高度な利活用を促進するためには、従来のクラウドによるデータ処理だけではなく、ネットワークの末端(エッジ)側において高度に低消費電力で情報処理を行う「エッジコンピューティング技術」の確立が求められています。
国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)では、「高効率・高速処理を可能とするAIチップ・次世代コンピューティングの技術開発/革新的AIエッジコンピューティング技術の開発」プロジェクトにおいて、日本が持つネットワーク末端機器(エッジデバイス)向け省電力化技術や個別の要素技術を生かしながら、大企業のみならず中小ベンチャー企業を含む産学連携体制によって、ハードウェアからアプリケーションまでを見越したエッジ側での超低消費電力エッジコンピューティング技術を開発することに取り組んでいます。
今回、NEDOと株式会社アラヤは、本プロジェクトの中の研究開発事業※1において、人工知能(AI)の深層学習用ニューラルネットワークモデルの精度をほぼ維持したまま、モデルサイズを最大約1/30に圧縮し、FPGA(Field Programmable Gate Array)※2に実装可能なソースコードを出力するという2つのプロセスを自動で行うツールを開発しました(図1)。これにより、自動車やスマートフォンなどのエッジデバイス上で、省電力・省スペースでリアルタイムでのAI処理が可能となります。また、圧縮や実装の工程が自動化されることにより、高度なAIの開発期間短縮や開発コストの低減を実現します。
本ツールは、11月20日から22日までパシフィコ横浜で開催されるIT展示会「ET & IoT Technology 2019」に、(株)アラヤが出展するほか、本展示会の表彰制度にて「Edge Technology優秀賞」の受賞が決定されています。
また、(株)アラヤは、本ツールを「Pressai(プレッサイ)」の名称で2020年3月に提供開始する予定です。
-
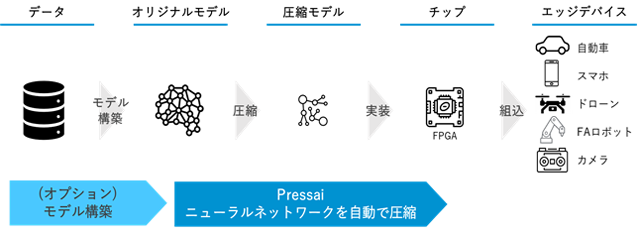 図1 エッジデバイスへのAI搭載プロセス
図1 エッジデバイスへのAI搭載プロセス
2.今回の成果
今回、(株)アラヤが従来保有していた演算量削減による深層学習モデルの圧縮技術を基礎とし、エッジデバイスへ複数種類の深層学習を実装するために、演算量削減技術と、FPGAに実装可能なソースコードを出力する技術の開発を行いました。
複数種類の深層学習モデル(物体検知や意味的領域分割、姿勢推定など)において、ニューラルネットワークの入力に近い層(Base Network層)は、ネットワーク構造(例えば、画像の汎用的な特徴を抽出する役割を担う構造)が同じような形をしているため、共通化することで演算量の削減が可能になります(図2(1))。
ネットワークの一部を共通化した統合モデルを、複数の手法を組み合わせて圧縮することで、さらに演算量を削減します(図2(2))。その際、ツールが学習と圧縮を交互に繰り返しながら自動で圧縮用パラメータを探索するので精度を維持した最適な圧縮が可能になり、最大約1/30に圧縮します。この圧縮結果を、FPGAに実装可能な形式のソースコードで出力します。
«圧縮実績例»
オリジナルモデル:超解像EDSR(baseline-x2)モデル、データセット:DIV2K、評価指標:PSNRの条件で、全体は3.54%に圧縮されましたが、精度はほぼ維持されました(非圧縮時34.64dB→圧縮時33.84dB)。
-
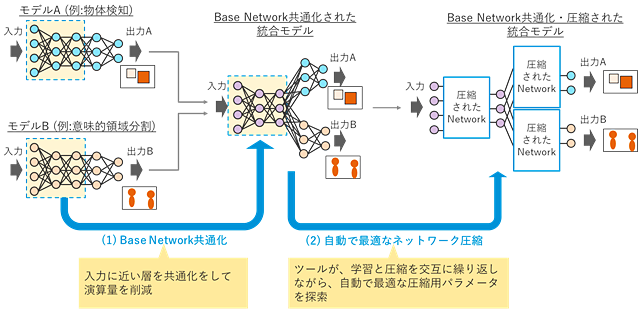 図2 Base Network共通化とネットワーク圧縮による演算量削減
図2 Base Network共通化とネットワーク圧縮による演算量削減
3.今後の予定
NEDOと(株)アラヤは今後、深層学習と強化学習を組み合わせた「深層強化学習※3」の対応にも取り組みます。深層強化学習は周辺の環境に応じて適切な制御(例えばドローン飛行制御)をするために、多様な環境をシミュレーターなどで用意し、学習を実施する必要があります。この課題を解決するために環境シミュレーターと連動した学習機能を持つ深層強化学習用ニューラルネットワークモデルの自動圧縮・実装ツールの開発にも取り組んでいきます。
【注釈】
- ※1 本プロジェクトの中の研究開発事業
- 事業名:高効率・高速処理を可能とするAIチップ・次世代コンピューティングの技術開発/革新的AIエッジコンピューティング技術の開発/5G時代を見据えた高度自律的学習機能搭載のためのAIエッジコンピューティング技術の研究開発
- ※2 FPGA(Field Programmable Gate Array)
- 内部の論理回路の構造を何度も繰り返し再構成できる半導体チップ(PLD:Programmable Logic Device)のうち、回路規模が数万ゲート以上に及ぶ大規模で複雑なものです。
- ※3 深層強化学習
- 深層学習による特徴抽出と、強化学習による予測制御を組み合わせ、ロボット制御などの複雑なシステムの制御ができるようになる技術。
4.問い合わせ先
(本ニュースリリースの内容についての問い合わせ先)
NEDO IoT推進部 担当:岡本、上野、大杉 TEL:044-520-5211
(株)アラヤ 広報担当:大江 E-mail:support@araya.org
(その他NEDO事業についての一般的な問い合わせ先)
NEDO 広報部 担当:佐藤、中里、坂本 TEL:044-520-5151 E-mail:nedo_press@ml.nedo.go.jp
関連ページ
- ネットワーク/コンピューティング
- 同分野のニュースリリースを探す
- 同分野の公募を探す
- 同分野のイベントを探す